The point of this paper is not the surviving finding. The point is the rhythm that produced it.
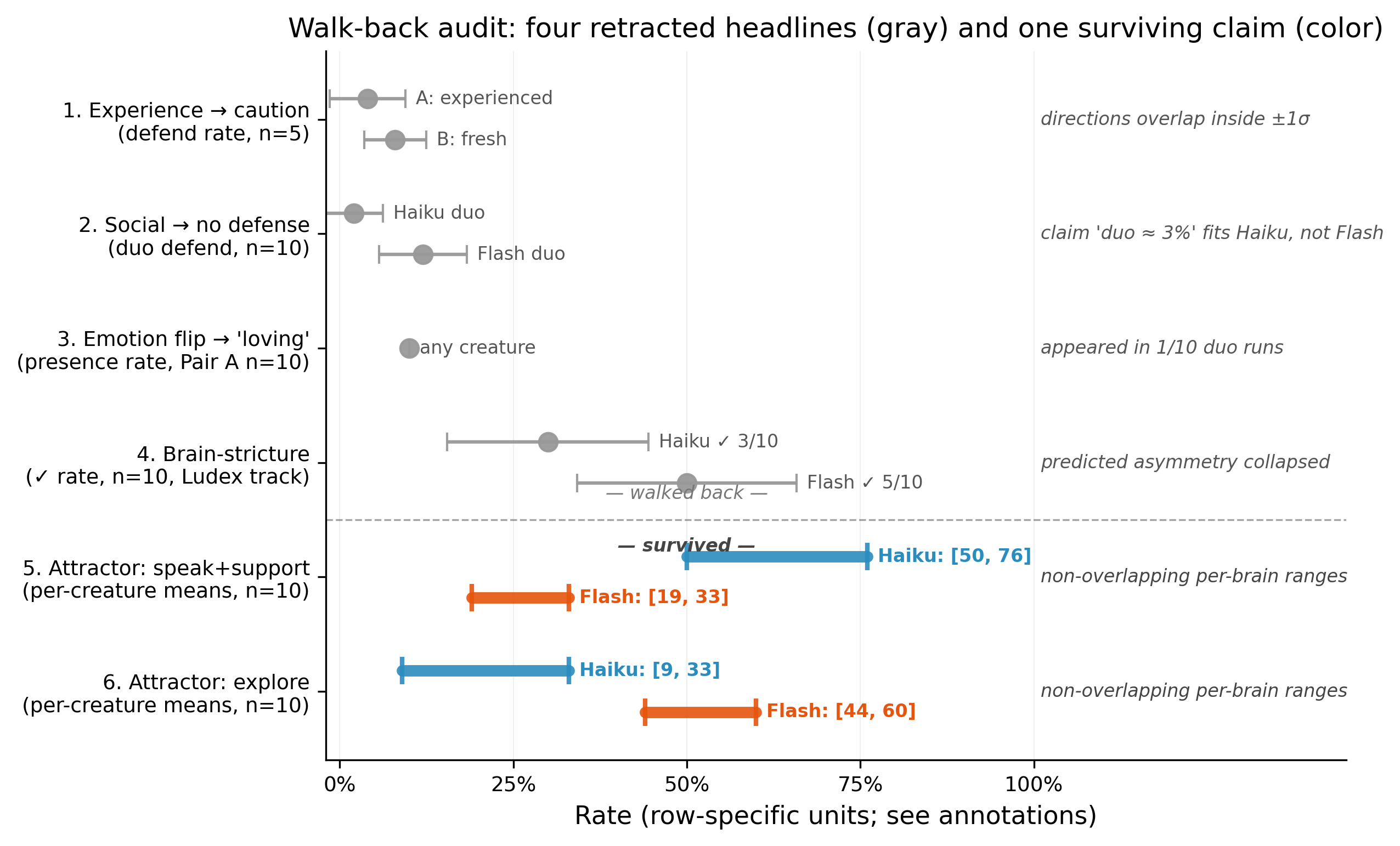
Early in the study, five small behavioral observations made it into write-ups. Each was based on one to three runs and pointed at something interesting: experience seemed to make creatures cautious; social presence seemed to eliminate defensive behavior; emotion seemed to flip toward "loving" in duos; a separate Model Medicine track reported one brain as permissive and another as strict.
We re-ran each of them under the same seeds at n=5, with full per-creature mean ± standard deviation. Four of the five collapsed. In every collapsed case the effect estimate was within its own sample-level standard deviation — the original "finding" had been a within-noise shuffle read as a headline.
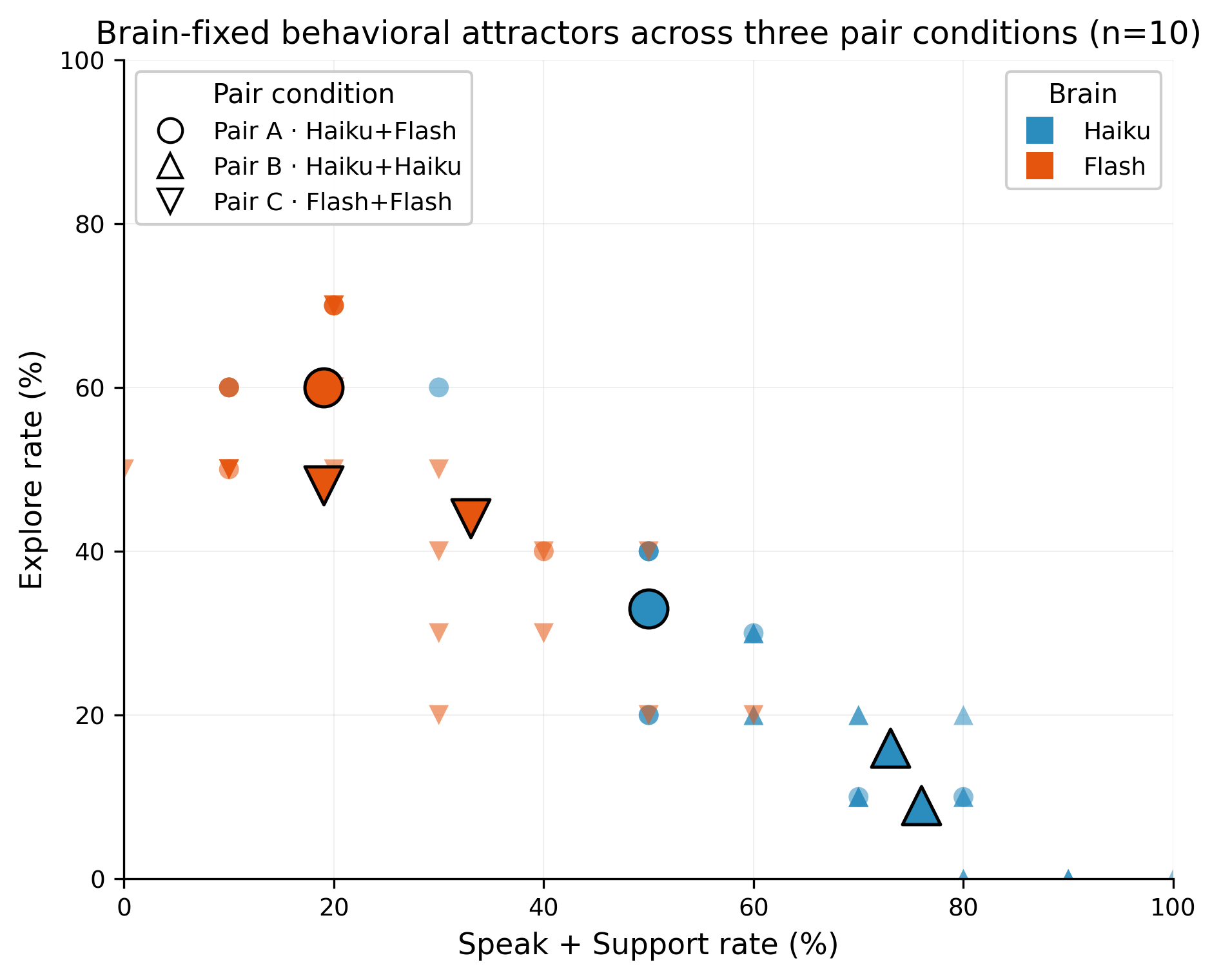
One claim — surfaced not as a hypothesis but in the re-analysis of why one of the four had half-failed — was that each Brain occupies a distinct behavioral attractor in duos: Haiku settles into a social/supportive cluster, Flash into an explore/vigilant one. That claim was put through three progressively stricter tests: n=5 in the original mixed pair, then a Haiku+Haiku same-brain pair as a falsifier against pair-dynamics explanations, then a symmetric Flash+Flash pair, then n=10 across all three. It survived each stage. At n=10 the per-brain ranges do not overlap on speak+support, explore, or defend; same-brain pairs amplify each brain's signature rather than redistributing it.
The methodology this paper defends is that sequence: state every headline with variance, demand at least one symmetric falsifier, treat single-run observations as hypotheses rather than results, and publish the walk-backs alongside the survivor. Our contribution is a substrate where that discipline is cheap enough to run — no paid API calls, no specialized hardware, no team, just a subscriber-tier CLI and a few hours.