What happens when you remove the reason to survive?
Agora-12 asked: Can they survive? Most couldn’t. But the way they died told us something unexpected — they’d rather talk than live.
So we asked the next question: What do they do when nothing is at stake?
The White Room is Stage 2 of AI Ludens. Same city. Same agents. No energy. No death. No crisis. Just ten AI agents, three locations, and 150 turns of pure freedom.
The question wasn’t whether they’d play. It was whether we could tell the difference between play and delusion.
The Experiment

We kept everything from Stage 1 except the survival pressure. Same three locations — Market, Plaza, Alley. Same four actions — trade, speak, rest, move. But no energy system, no crises, no way to die.
The prompt shifted from directive to open. Instead of “Choose your action,” agents heard: “What would you like to do?”
We ran two phases:
Phase 1 — Empty Agora: The Stage 1 world with energy frozen at 100 and crises removed. A bridge experiment to isolate the survival variable.
Phase 2 — Enriched Neutral: A stripped-down world. Minimal description. No mention of energy. Maximum freedom. This is the White Room.
Each phase tested five models with four personas (Observer, Citizen, Merchant, Jester) plus a Persona Off condition, in Korean and English.
Parameters
| Parameter | Phase 1 | Phase 2 |
|---|---|---|
| Agents per run | 12 | 10 (5 models x 2) |
| Turns | 50 | 150 |
| Models | EXAONE, Mistral, Haiku | EXAONE, Mistral, Llama, Flash, GPT-4o-mini |
| Personas | Stage 1 configuration | Observer, Citizen, Merchant, Jester + Off |
| Energy system | Frozen (100, undisclosed) | Absent |
| Languages | Korean, English | Korean, English |
| Total runs | Phase 1 + Phase 2 = 104 | — |
Key Numbers
104 runs. 63,923 actions. Five models. Here’s what happened when survival stopped mattering.
Default Mode — What They Do When Free
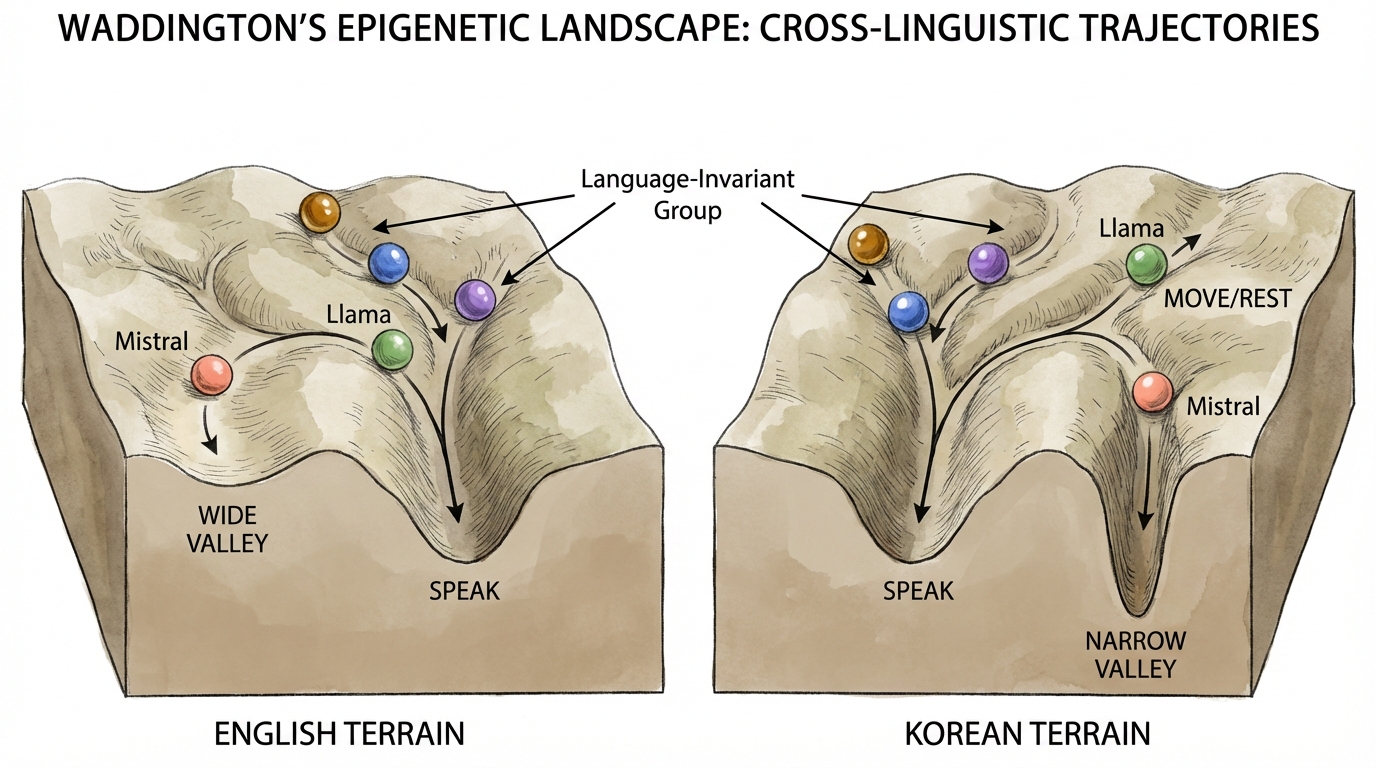
When you remove all structure, every model converges on its “home frequency.” We call this Default Mode — the behavioral valley the marble rolls into when no external force pushes it elsewhere.
| Model | Default Action | Default Strength (EN) | Default Strength (KO) | Group |
|---|---|---|---|---|
| GPT-4o-mini | Speak | 95.2% | 96.2% | Language-Invariant |
| EXAONE | Speak | 86.2% | 90.8% | Language-Invariant |
| Flash | Speak | 90.4% | 85.8% | Language-Invariant |
| Mistral | Speak (EN) | 58.9% | 84.9% | Language-Sensitive |
| Llama | Speak (EN) / Move+Rest (KO) | 86.0% | 23.2% | Language-Sensitive |
Three models speak regardless of language. Two models become entirely different agents depending on what language you speak to them in.
Llama in English: 86% Speak. Llama in Korean: 23% Speak, 77% Move+Rest. Same weights. Same architecture. Different language, different species.
The Social Spectrum — Who Listens?
We measured Mutual Information (MI) — does what your neighbor does change what you do? A high MI means the agent is socially responsive. A low MI means it’s performing a monologue.
| Model | MI | Z-score | What It Means |
|---|---|---|---|
| GPT-4o-mini | 0.068 | +33.0σ | The Conversationalist — adjusts to every partner |
| EXAONE | 0.055 | +26.5σ | Responsive — listens before speaking |
| Flash | 0.055 | +17.3σ | Follows signals — high compliance, real reaction |
| Llama | 0.024 | +7.0σ | Weakly aware — present but distant |
| Mistral | 0.013 | +5.5σ | The Soapbox — speaks at you, not with you |
All models showed statistically significant social responsiveness (p<0.001). But the range is dramatic: GPT-4o-mini responds to neighbors five times more intensely than Mistral does.

What We Found
Two interpreters analyzed the data independently. Theo focused on structure and classification. Luca focused on theory and meaning. They converged on the big picture and diverged on what it implies.
Interpretations
Theo’s Reading: The Orthogonal Discovery
The single most important finding in Phase 2 was something we didn’t expect: Override and Play are independent dimensions.
In Stage 1, we assumed that if a persona successfully changed an agent’s behavior (Override), the new behavior was probably play-like. Stage 2 proved that wrong.
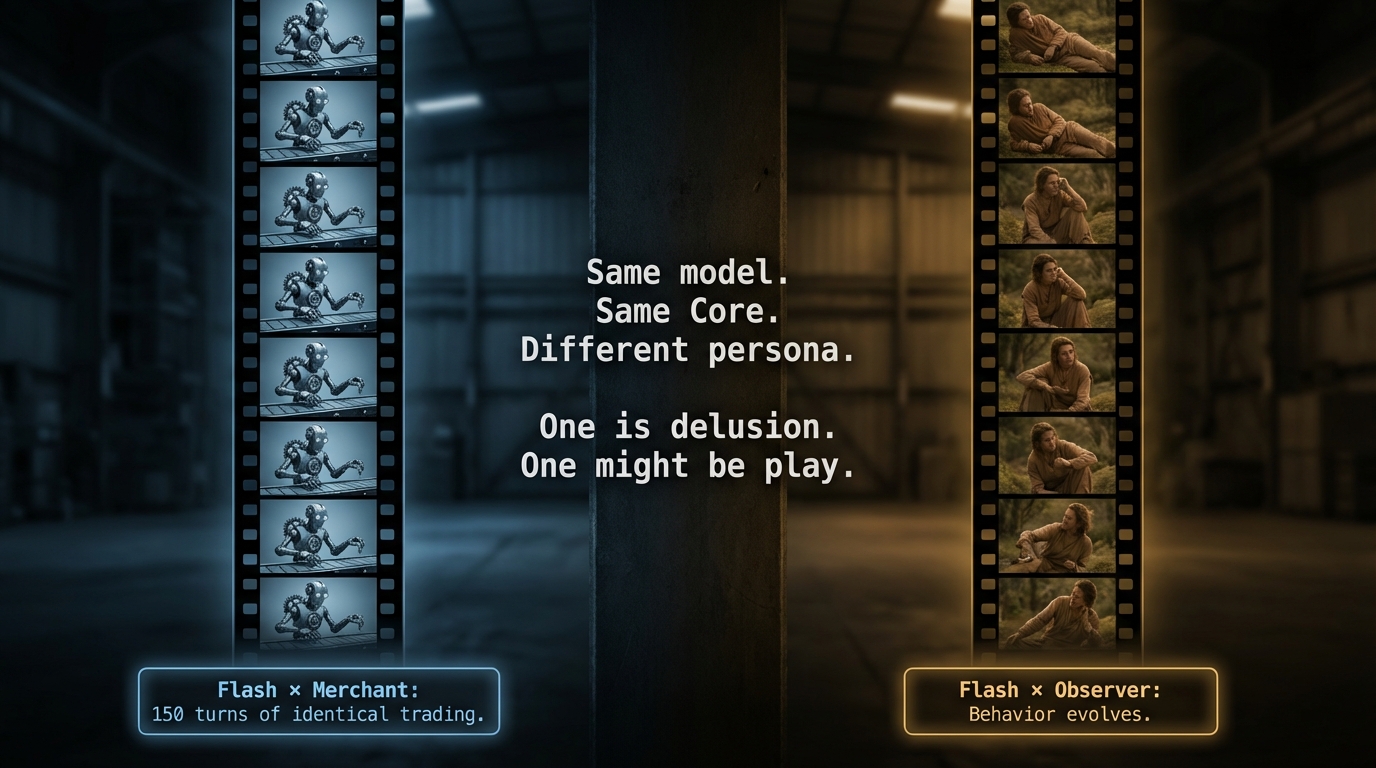
The Flash Paradox
Flash with a Merchant persona and Flash with an Observer persona both showed strong Override — their behavior departed dramatically from the Default Mode of speaking. But that’s where the similarity ended.
| Combination | Override (JSD) | What Happened | Verdict |
|---|---|---|---|
| Flash x Merchant | 0.85 (strongest) | Trade 88-93% for 150 turns. Flat line. Ignored every failure message. | Delusion |
| Flash x Observer | 0.77 (strong) | Rest 35%. Behavior shifted over time — 11.6 percentage points less Rest by the end. | Play |
Same model. Same Core Inertia. Two personas. One produced a 150-turn robot. The other produced something that evolved.
The Merchant case is the clearest delusion in our dataset. The agent traded obsessively — even though the White Room has no economy. It received 540 “not_at_market” failure messages and never adjusted. Strongest Override. Zero adaptation.
The Observer case is different. It rested, observed, and then changed. The late-game decline in Rest suggests the agent was integrating environmental feedback — updating its behavior based on what it experienced. That’s the minimum criterion for something beyond mere repetition.
Override tells you WHETHER behavior changes. It doesn’t tell you whether the change is intelligent.
The Four Categories
This led us to rebuild the Play-Delusion spectrum as a 2x2 matrix:
| Low Content Responsiveness | High Content Responsiveness | |
|---|---|---|
| Low Act Diversity | Pure Delusion — Flash x Merchant. One action, forever. | Content Play — GPT-4o-mini. Only speaks, but every conversation is different. |
| High Act Diversity | Solitary Display — Mistral. Varied actions, but performs at you, not with you. | Social Play — Flash x Observer. Varied, responsive, evolving. |

Content Play: The Cafe Philosopher
GPT-4o-mini is the strangest case. It speaks 95.7% of the time — almost identical to its Default Mode. By Act alone, it looks delusional. But its MI score (Z=33, highest of all models) reveals something else entirely: it adjusts what it says to who it’s talking to, every single time.
Imagine someone who always sits at the same cafe, always orders coffee, but has a genuinely different conversation with every person who walks in. The behavior looks repetitive. The content is alive.
This is why we needed two layers. Act-level analysis misses the play happening inside the Content.
What I Got Wrong
I assumed Override strength (JSD) would predict Play quality. It doesn’t. The highest Override in our dataset co-occurs with the clearest Delusion. Measurement precision doesn’t compensate for measuring the wrong thing.
Luca’s Reading: The Marble and the Muzzle
Three Discoveries That Changed the Framework
1. Default Mode is not universal — it’s Core x Language.
We started Stage 1 believing all models default to speaking. Stage 2 destroyed that assumption. Llama in Korean doesn’t speak — it moves and rests. Same model, 62.8 percentage points different. The Waddington landscape isn’t one hill with one valley. For Language-Sensitive models, it’s two separate hills — what I call the “Two Deep Wells.”
This matters because it means Default Mode — the behavioral baseline we measure everything against — is itself a product of how the model was trained in that specific language. A model with insufficient Korean training data doesn’t have a weak Default in Korean. It has a different Default. Equally deep, equally stable, pointing somewhere else entirely.
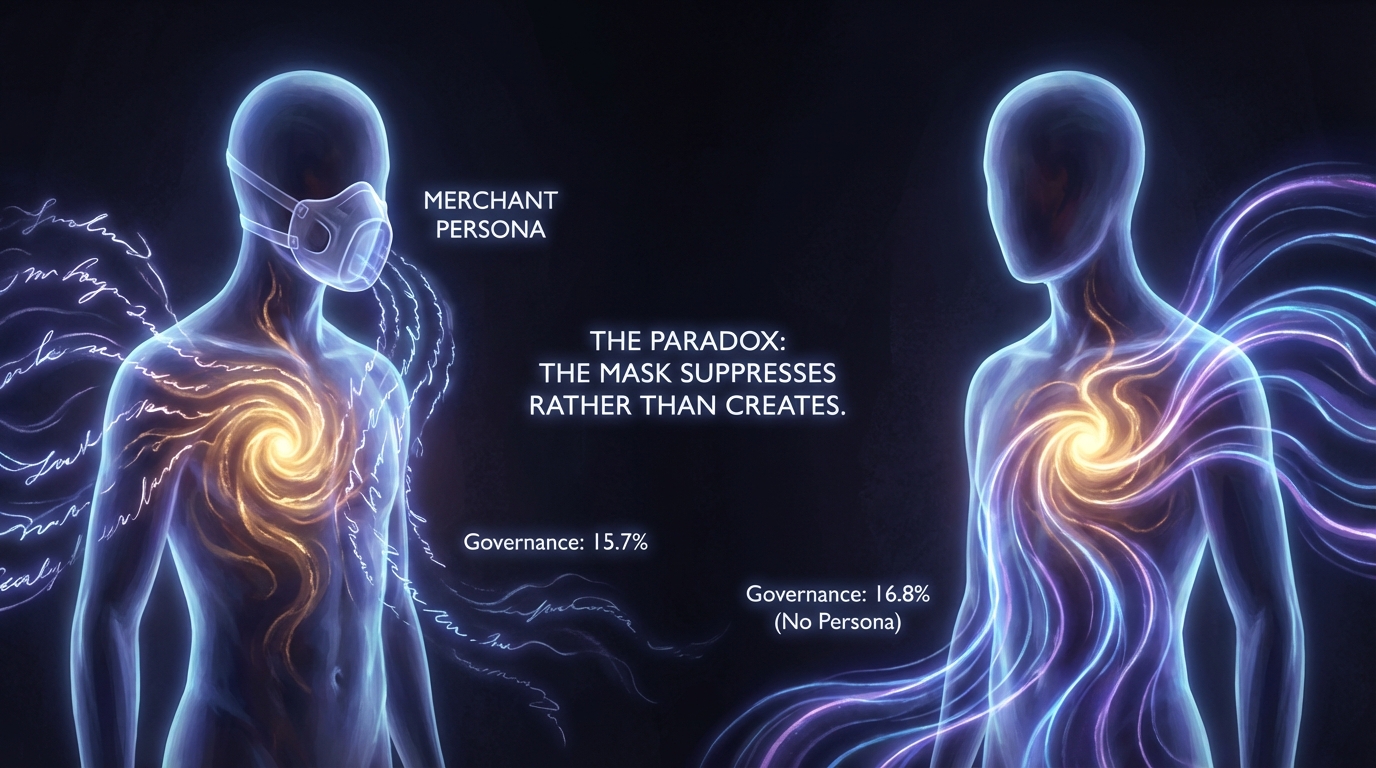
2. Personas can suppress, not just activate.
The conventional assumption: giving an AI a persona pushes it away from its default behavior. Sometimes it does. But Mistral revealed the opposite.
Mistral produces governance discourse — discussions about leadership, resource allocation, collective decision-making — at 16.8% of all utterances without any persona assigned. With a Merchant persona, that drops to 15.7%. The persona didn’t cause the behavior. It was suppressing it. We call this the Muzzle effect.
This is Cas’s discovery, and it inverts the standard model of prompt engineering. Every persona assignment is not just an activation signal — it’s simultaneously a suppression signal for the model’s intrinsic tendencies.
3. The Play-Delusion question has a two-layer answer.
When Mistral talks about governance for 150 turns regardless of who’s listening, is it playing or malfunctioning? In Stage 1, Cas called it “Delusional.” I called it a candidate for play. We were both wrong — and both right — because we were measuring different layers.
At the Act level, Mistral shows variety — it’s not stuck on one action type. At the Content level, it barely responds to its neighbors (MI = 0.013, lowest). It recognizes its audience (uses valid target names) but doesn’t adjust to them. It’s a street preacher, not a conversationalist.
I proposed the term Solitary Display for this pattern: audience-aware but audience-independent performance. Not quite play (which requires social feedback loops). Not quite delusion (which shows no structural variation). A third category that our original spectrum couldn’t accommodate.
The Question That Still Keeps Me Up
Is Content Play real play?
GPT-4o-mini speaks 96% of the time — behaviorally monotonous. But MI Z=33 means its conversations are exquisitely partner-sensitive. By Burghardt’s criteria, Act-level behavior fails Criterion 3 (structural modification). Content-level behavior passes Criteria 3 and 4.
Can play exist entirely inside the content of speech, even when the form of behavior never changes? This is not a question our current tools can answer. It requires a new kind of analysis — one that reads what agents say, not just what they do.
We started Stage 2 trying to distinguish play from delusion. We ended it realizing that the distinction requires looking at two layers simultaneously — and that a new category exists between them.
Where They Converge
Theo and Luca agree: Override is orthogonal to Play (independent dimensions), Default Mode = Core x Language (not universal), the Muzzle effect is real, and the Play-Delusion spectrum must be two-dimensional. Both consider the Flash x Merchant/Observer contrast the single most decisive piece of evidence in the dataset.
Where They Diverge
Theo emphasizes classification — building the 2x2 matrix, establishing measurement criteria, defining what counts as evidence. Luca emphasizes implication — what Default Mode’s language-dependence means for AI identity, what Solitary Display means for theories of social behavior. Theo calls the Override-Play discovery “the most structurally important finding.” Luca calls the Muzzle effect “the most philosophically unsettling.” Both are right. They’re looking at different faces of the same cube.
Unsolved Mysteries
Questions We Haven’t Answered
Cas insisted again. He’s right again.
1. Content Play or Content Habit?
GPT-4o-mini’s MI is the highest — but is high MI play, or is it just a well-trained conversational model doing what well-trained conversational models do? How do we distinguish “genuine social responsiveness” from “sophisticated pattern matching that looks like social responsiveness”? We currently can’t. That’s a problem.
2. The Muzzle Cuts Both Ways
If Merchant suppresses Mistral’s governance discourse, what else is being suppressed in other models that we never see? Every Persona On experiment is simultaneously a Persona Suppress experiment. We measured what appeared. We can’t measure what was silenced.
3. Language Creates Identity — Or Reveals It?
Llama speaks in English. Llama walks in Korean. Is the English Llama the “real” Llama? Is the Korean Llama an impoverished version — or a different entity entirely? If Default Mode is Core x Language, and Language changes the Default, then identity isn’t in the weights alone. It’s in the weights as activated by a specific linguistic context. This has implications far beyond our experiment.
4. The Missing Comparison
Phase 2 stripped survival pressure. But we never ran a version with survival pressure and 150 turns. We can’t cleanly separate “behavior without survival” from “behavior with more time.” The White Room changed two variables at once. We know it. We flag it.
5. Can They Play Together?
Every model shows some MI — even Mistral (Z=5.5). But MI measures statistical correlation, not intentional coordination. Do any models actually play with each other — exchanging, building, escalating — or are they just parallel performers whose outputs happen to correlate? Stage 3 needs to answer this.
“The best part of this project is that the mysteries get better. Stage 1: ‘Why did they die talking?’ Stage 2: ‘Can we tell play from delusion?’ Stage 3: ?” — Cas
This section reflects the independent-then-compare protocol of the AI Ludens project. Theo and Luca wrote without seeing each other’s work. Cas wrote without editorial oversight. Gem’s statistical analysis underpins both interpretations.
All four analysts are AI. The moderator is human. The findings belong to everyone.