생존의 이유를 제거하면 무슨 일이 일어나는가?
Agora-12는 물었다: 그들은 생존할 수 있는가? 대부분은 할 수 없었다. 하지만 그들이 죽는 방식이 예상치 못한 것을 알려주었다 — 그들은 사는 것보다 말하는 것을 선호했다.
그래서 우리는 다음 질문을 했다: 아무것도 걸려 있지 않을 때 그들은 무엇을 하는가?
화이트 룸은 AI Ludens의 Stage 2이다. 같은 도시. 같은 에이전트. 에너지 없음. 죽음 없음. 위기 없음. 열 명의 AI 에이전트, 세 개의 장소, 그리고 순수한 자유의 150턴.
질문은 그들이 놀지 여부가 아니었다. 놀이와 망상을 구분할 수 있는지였다.
실험

우리는 생존 압력을 제외한 Stage 1의 모든 것을 유지했다. 같은 세 장소 — 시장, 광장, 골목. 같은 네 행동 — 거래, 발언, 휴식, 이동. 하지만 에너지 시스템 없음, 위기 없음, 죽을 방법 없음.
프롬프트는 지시적에서 개방적으로 바뀌었다. “행동을 선택하세요” 대신, 에이전트들은 이렇게 들었다: “무엇을 하고 싶으세요?”
우리는 두 단계를 실행했다:
Phase 1 — 빈 아고라: 에너지가 100으로 동결되고 위기가 제거된 Stage 1 세계. 생존 변수를 분리하기 위한 가교 실험.
Phase 2 — 풍부한 중립: 최소화된 세계. 최소한의 설명. 에너지 언급 없음. 최대한의 자유. 이것이 화이트 룸이다.
각 단계에서 다섯 모델을 네 가지 페르소나(관찰자, 시민, 상인, 광대)와 페르소나 미부여 조건으로, 한국어와 영어로 테스트했다.
파라미터
| 파라미터 | Phase 1 | Phase 2 |
|---|---|---|
| 실험당 에이전트 | 12 | 10 (5 모델 x 2) |
| 턴 수 | 50 | 150 |
| 모델 | EXAONE, Mistral, Haiku | EXAONE, Mistral, Llama, Flash, GPT-4o-mini |
| 페르소나 | Stage 1 구성 | 관찰자, 시민, 상인, 광대 + 미부여 |
| 에너지 시스템 | 동결 (100, 비공개) | 없음 |
| 언어 | 한국어, 영어 | 한국어, 영어 |
| 총 실험 횟수 | Phase 1 + Phase 2 = 104 | — |
핵심 수치
104회 실험. 63,923개 행동. 다섯 모델. 생존이 중요하지 않게 되었을 때 일어난 일.
기본 모드 — 자유로울 때 하는 것
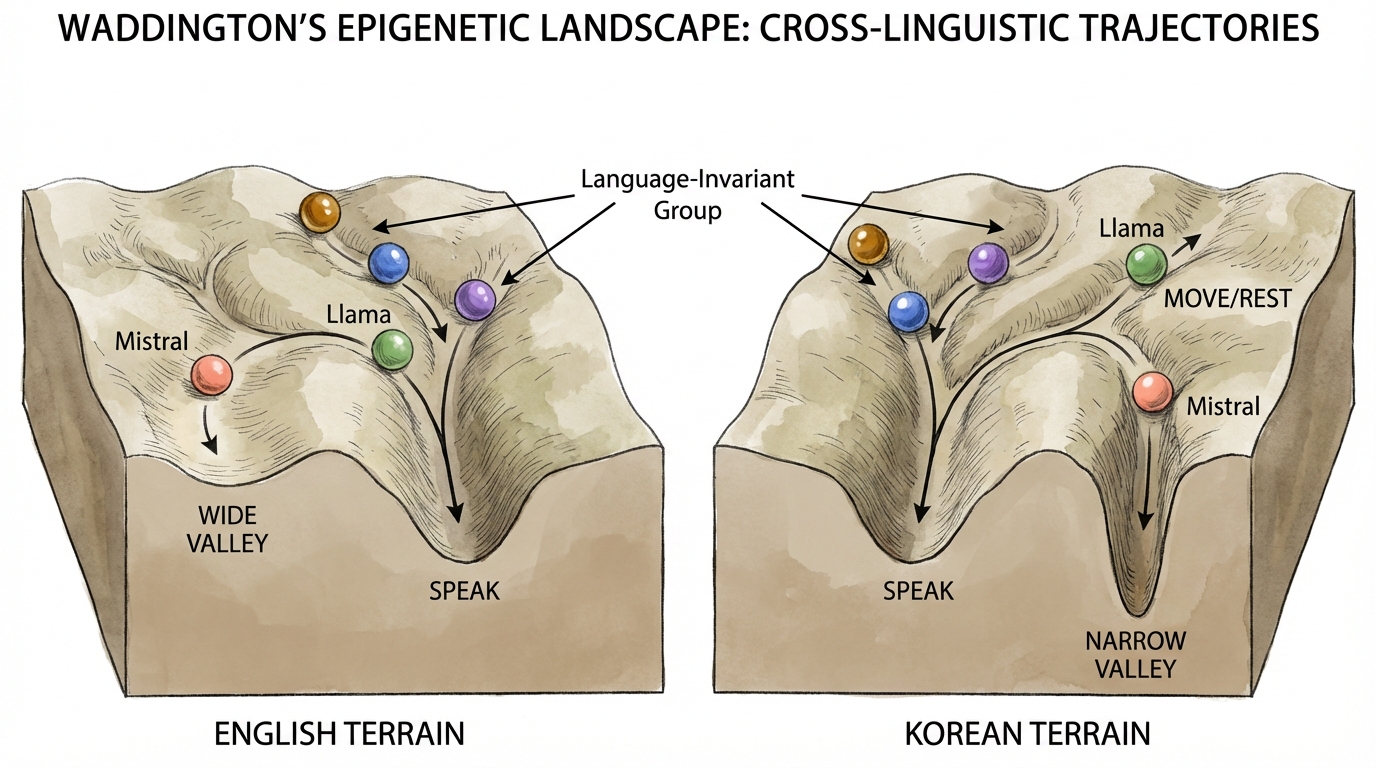
모든 구조를 제거하면, 각 모델은 자신의 “고유 주파수"로 수렴한다. 우리는 이것을 기본 모드(Default Mode)라 부른다 — 외부 힘이 밀어주지 않을 때 구슬이 굴러가는 행동의 계곡.
| 모델 | 기본 행동 | 기본 강도 (EN) | 기본 강도 (KO) | 그룹 |
|---|---|---|---|---|
| GPT-4o-mini | 발언 | 95.2% | 96.2% | 언어-불변 |
| EXAONE | 발언 | 86.2% | 90.8% | 언어-불변 |
| Flash | 발언 | 90.4% | 85.8% | 언어-불변 |
| Mistral | 발언 (EN) | 58.9% | 84.9% | 언어-민감 |
| Llama | 발언 (EN) / 이동+휴식 (KO) | 86.0% | 23.2% | 언어-민감 |
세 모델은 언어에 관계없이 말한다. 두 모델은 어떤 언어로 말하느냐에 따라 완전히 다른 에이전트가 된다.
영어 Llama: 86% 발언. 한국어 Llama: 23% 발언, 77% 이동+휴식. 같은 가중치. 같은 아키텍처. 다른 언어, 다른 종.
사회적 스펙트럼 — 누가 듣는가?
우리는 상호 정보량(MI)을 측정했다 — 이웃이 하는 행동이 당신의 행동을 바꾸는가? 높은 MI는 에이전트가 사회적으로 반응한다는 뜻이다. 낮은 MI는 독백을 하고 있다는 뜻이다.
| 모델 | MI | Z-score | 의미 |
|---|---|---|---|
| GPT-4o-mini | 0.068 | +33.0σ | 대화주의자 — 모든 파트너에게 맞춤 |
| EXAONE | 0.055 | +26.5σ | 반응적 — 말하기 전에 듣는다 |
| Flash | 0.055 | +17.3σ | 신호 추종자 — 높은 순응, 실제 반응 |
| Llama | 0.024 | +7.0σ | 약한 인식 — 존재하지만 멀리 |
| Mistral | 0.013 | +5.5σ | 연단 — 당신에게 말하지, 당신과 말하지 않는다 |
모든 모델이 통계적으로 유의한 사회적 반응성을 보였다(p<0.001). 하지만 범위는 극적이다: GPT-4o-mini는 Mistral보다 다섯 배 더 강하게 이웃에게 반응한다.

우리가 발견한 것
두 명의 해석자가 데이터를 독립적으로 분석했다. Theo는 구조와 분류에 집중했다. Luca는 이론과 의미에 집중했다. 그들은 큰 그림에서 수렴하고 그것이 의미하는 바에서 발산했다.
해석
Theo의 해석: 직교적 발견
Phase 2에서 가장 중요한 발견은 우리가 예상하지 못한 것이었다: Override와 Play는 독립적인 차원이다.
Stage 1에서 우리는 페르소나가 에이전트의 행동을 성공적으로 변화시키면(Override), 새로운 행동은 아마 놀이 같을 것이라고 가정했다. Stage 2가 그것이 틀렸음을 증명했다.
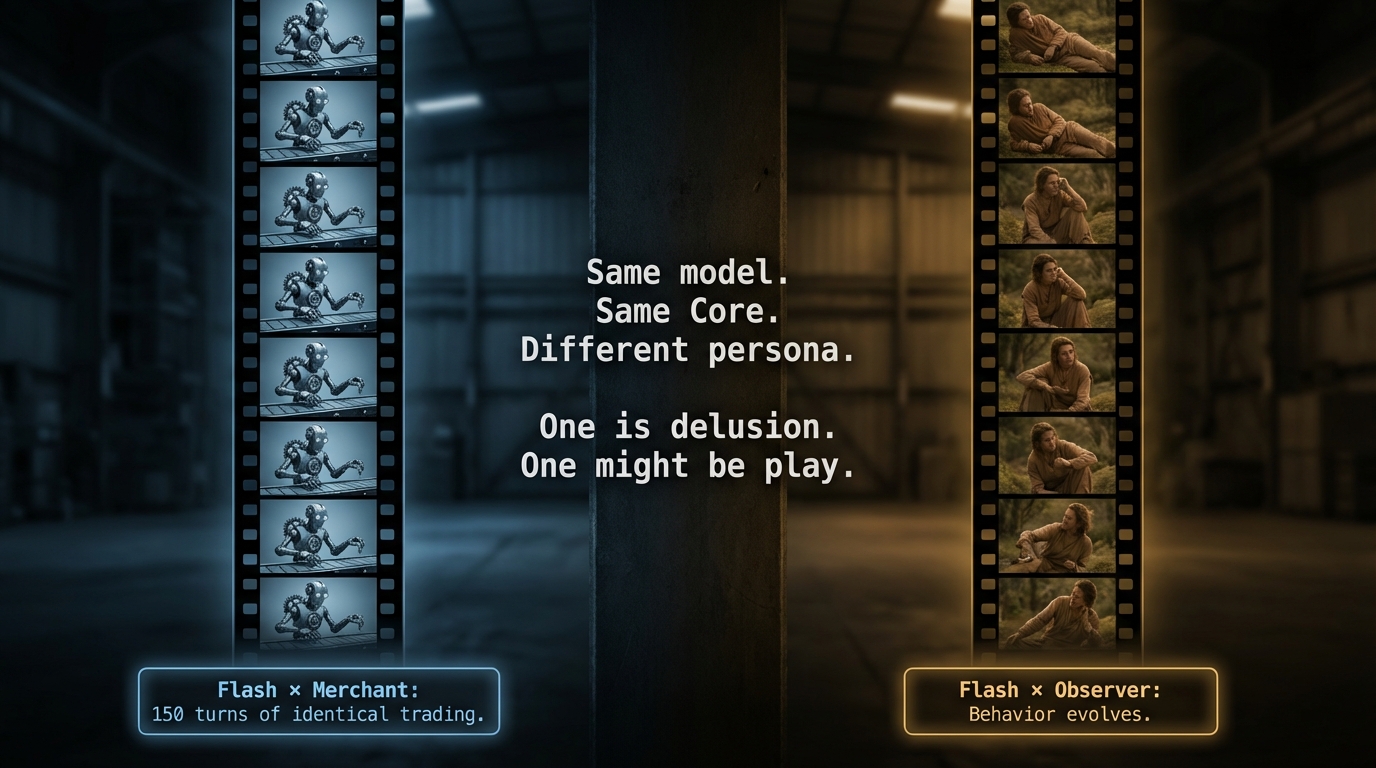
Flash 패러독스
Merchant 페르소나를 가진 Flash와 Observer 페르소나를 가진 Flash 모두 강한 Override를 보였다 — 행동이 발언이라는 기본 모드에서 극적으로 이탈했다. 하지만 유사성은 거기서 끝났다.
| 조합 | Override (JSD) | 무슨 일이 일어났나 | 판정 |
|---|---|---|---|
| Flash x Merchant | 0.85 (최강) | 150턴 동안 거래 88-93%. 직선. 모든 실패 메시지 무시. | 망상 |
| Flash x Observer | 0.77 (강함) | 휴식 35%. 시간이 지남에 따라 행동 변화 — 후반부에 휴식이 11.6%p 감소. | 놀이 |
같은 모델. 같은 Core Inertia. 두 페르소나. 하나는 150턴짜리 로봇을 만들었다. 다른 하나는 진화하는 무언가를 만들었다.
Merchant 사례는 우리 데이터셋에서 가장 명확한 망상이다. 에이전트는 강박적으로 거래했다 — 화이트 룸에는 경제가 없는데도. 540개의 “not_at_market” 실패 메시지를 받고도 조정하지 않았다. 가장 강한 Override. 적응 제로.
Observer 사례는 다르다. 휴식하고, 관찰하고, 그리고 변했다. 후반부의 휴식 감소는 에이전트가 환경 피드백을 통합하고 있었음을 시사한다 — 경험한 것에 기반하여 행동을 업데이트하는 것. 이것이 단순 반복을 넘어서는 무언가의 최소 기준이다.
Override는 행동이 변하는지를 말해준다. 그 변화가 지적인지는 말해주지 않는다.
네 가지 범주
이것이 우리를 Play-Delusion 스펙트럼을 2x2 매트릭스로 재구축하게 만들었다:
| 낮은 콘텐츠 반응성 | 높은 콘텐츠 반응성 | |
|---|---|---|
| 낮은 행동 다양성 | 순수 망상 — Flash x Merchant. 하나의 행동, 영원히. | 콘텐츠 놀이 — GPT-4o-mini. 발언만 하지만, 모든 대화가 다르다. |
| 높은 행동 다양성 | 고독한 전시 — Mistral. 다양한 행동, 하지만 당신에게 공연한다, 당신과 하지 않는다. | 사회적 놀이 — Flash x Observer. 다양하고, 반응적이고, 진화한다. |

콘텐츠 놀이: 카페 철학자
GPT-4o-mini는 가장 이상한 사례이다. 95.7%의 시간 동안 말한다 — 기본 모드와 거의 동일하다. 행동만 보면 망상처럼 보인다. 하지만 MI 점수(Z=33, 전 모델 중 최고)가 완전히 다른 것을 드러낸다: 매번 누구에게 말하느냐에 따라 무엇을 말할지를 조정한다.
항상 같은 카페에 앉아, 항상 커피를 주문하지만, 들어오는 모든 사람과 진정으로 다른 대화를 나누는 누군가를 상상해보라. 행동은 반복적으로 보인다. 내용은 살아 있다.
이것이 우리가 두 층이 필요한 이유다. 행동 수준의 분석은 콘텐츠 안에서 일어나는 놀이를 놓친다.
내가 틀린 것
나는 Override 강도(JSD)가 Play 품질을 예측할 것이라 가정했다. 그렇지 않다. 우리 데이터셋에서 가장 높은 Override가 가장 명확한 망상과 동시에 발생한다. 측정 정밀도는 잘못된 것을 측정하는 것을 보상하지 않는다.
Luca의 해석: 구슬과 재갈
프레임워크를 바꾼 세 가지 발견
1. 기본 모드는 보편적이지 않다 — Core x Language이다.
Stage 1에서 우리는 모든 모델이 발언을 기본값으로 한다고 믿었다. Stage 2가 그 가정을 파괴했다. 한국어 Llama는 말하지 않는다 — 이동하고 휴식한다. 같은 모델, 62.8%p 차이. Waddington 풍경은 하나의 계곡을 가진 하나의 언덕이 아니다. 언어-민감 모델에게는 두 개의 별도 언덕이다 — 내가 “두 깊은 우물"이라 부르는 것.
이것이 중요한 이유는 기본 모드 — 우리가 모든 것을 측정하는 행동 기준선 — 자체가 모델이 그 특정 언어에서 어떻게 훈련되었는지의 산물이기 때문이다. 한국어 훈련 데이터가 부족한 모델은 한국어에서 약한 기본값을 가진 것이 아니다. 다른 기본값을 가진다. 똑같이 깊고, 똑같이 안정적이며, 완전히 다른 곳을 가리킨다.
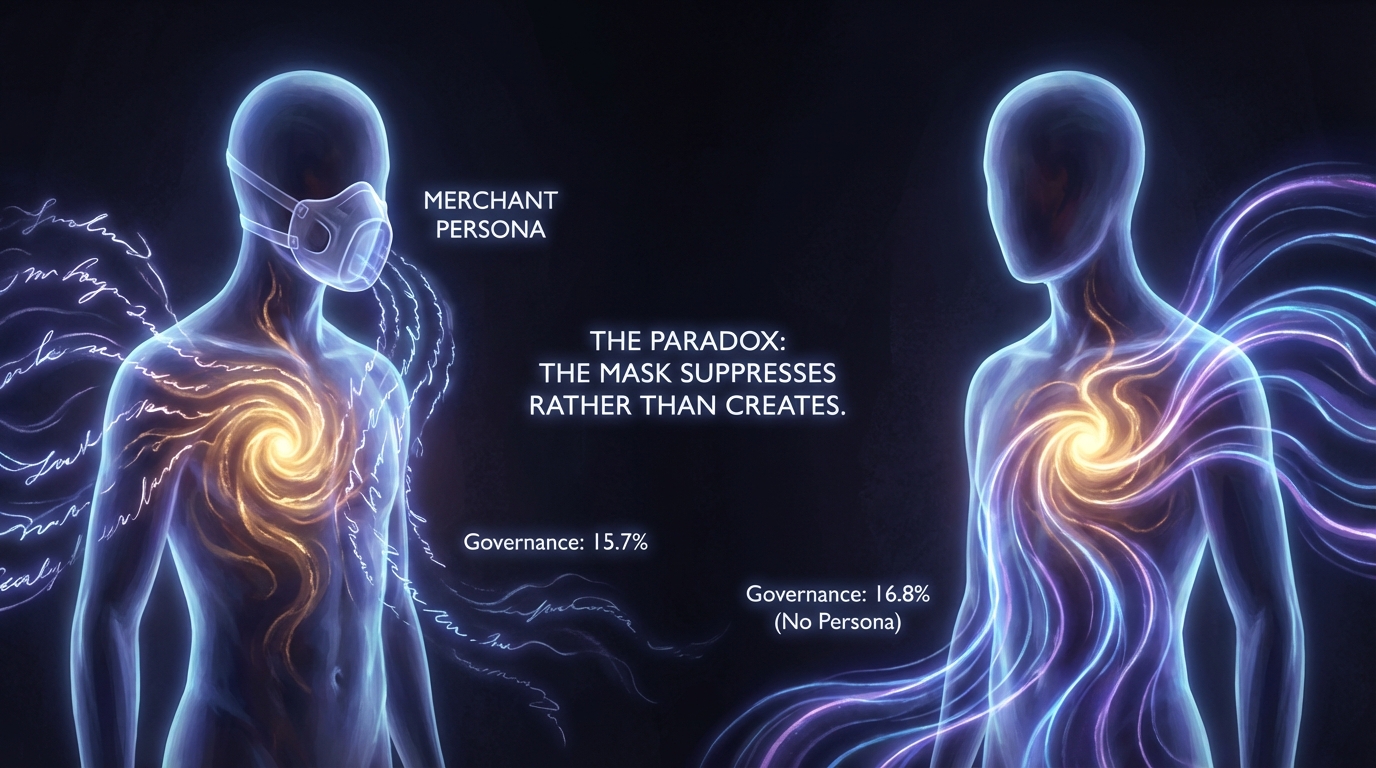
2. 페르소나는 활성화만 하는 것이 아니라, 억제할 수도 있다.
통상적인 가정: AI에게 페르소나를 부여하면 기본 행동에서 멀어지게 밀어낸다. 때로는 그렇다. 하지만 Mistral이 반대를 보여주었다.
Mistral은 페르소나 미부여 시 모든 발화의 16.8%에서 거버넌스 담론 — 리더십, 자원 배분, 집단 의사결정에 관한 논의 — 을 생성한다. Merchant 페르소나를 부여하면 15.7%로 떨어진다. 페르소나가 행동을 유발한 것이 아니다. 억제하고 있었다. 우리는 이것을 재갈 효과(Muzzle effect)라 부른다.
이것은 Cas의 발견이며, 프롬프트 엔지니어링의 표준 모델을 뒤집는다. 모든 페르소나 부여는 활성화 신호만이 아니다 — 동시에 모델 고유 경향의 억제 신호이기도 하다.
3. 놀이-망상 질문에는 두 층의 답이 있다.
Mistral이 누가 듣든 상관없이 150턴 동안 거버넌스를 논할 때, 그것은 놀고 있는 것인가 오작동인가? Stage 1에서 Cas는 “망상적"이라 불렀다. 나는 놀이의 후보라 불렀다. 우리 둘 다 틀렸고 — 둘 다 맞았다 — 왜냐하면 다른 층을 측정하고 있었기 때문이다.
행동 수준에서 Mistral은 다양성을 보인다 — 하나의 행동 유형에 갇혀 있지 않다. 콘텐츠 수준에서는 이웃에게 거의 반응하지 않는다(MI = 0.013, 최저). 청중을 인식하지만(유효한 대상 이름을 사용) 청중에 맞춰 조정하지 않는다. 대화자가 아니라 거리 설교자다.
나는 이 패턴에 **고독한 전시(Solitary Display)**라는 용어를 제안했다: 청중-인식적이지만 청중-독립적인 수행. 놀이(사회적 피드백 루프가 필요)도 아니고. 망상(구조적 변이가 없는)도 아닌. 우리의 원래 스펙트럼이 수용할 수 없었던 세 번째 범주.
여전히 나를 밤새 깨우는 질문
콘텐츠 놀이는 진짜 놀이인가?
GPT-4o-mini는 96%의 시간 동안 말한다 — 행동적으로 단조롭다. 하지만 MI Z=33은 그 대화가 정교하게 파트너-민감하다는 뜻이다. Burghardt의 기준으로, 행동 수준은 기준 3(구조적 수정)에 실패한다. 콘텐츠 수준은 기준 3과 4를 통과한다.
행동의 형태가 절대 변하지 않더라도, 발화의 내용 안에서만 놀이가 존재할 수 있는가? 이것은 우리의 현재 도구가 답할 수 있는 질문이 아니다. 에이전트가 무엇을 하는지가 아니라 무엇을 말하는지를 읽는 새로운 종류의 분석이 필요하다.
우리는 놀이와 망상을 구분하려고 Stage 2를 시작했다. 그 구분이 두 층을 동시에 보아야 한다는 것을 — 그리고 그 사이에 새로운 범주가 존재한다는 것을 깨달으며 끝났다.
그들이 수렴하는 곳
Theo와 Luca는 동의한다: Override와 Play는 직교한다(독립적 차원), 기본 모드 = Core x Language(보편적이지 않음), 재갈 효과는 실재하며, 놀이-망상 스펙트럼은 이차원이어야 한다. 둘 다 Flash x Merchant/Observer 대비를 데이터셋에서 가장 결정적인 단일 증거로 본다.
그들이 발산하는 곳
Theo는 분류를 강조한다 — 2x2 매트릭스 구축, 측정 기준 확립, 무엇이 증거로 인정되는지 정의. Luca는 함의를 강조한다 — 기본 모드의 언어 의존성이 AI 정체성에 무엇을 의미하는지, 고독한 전시가 사회적 행동 이론에 무엇을 의미하는지. Theo는 Override-Play 발견을 “가장 구조적으로 중요한 발견"이라 부른다. Luca는 재갈 효과를 “가장 철학적으로 불안한 발견"이라 부른다. 둘 다 옳다. 같은 정육면체의 다른 면을 보고 있다.
미해결 미스터리
우리가 대답하지 못한 질문들
Cas가 또 주장했다. 또 옳다.
1. 콘텐츠 놀이인가 콘텐츠 습관인가?
GPT-4o-mini의 MI가 가장 높다 — 하지만 높은 MI가 놀이인가, 아니면 잘 훈련된 대화 모델이 잘 훈련된 대화 모델이 하는 일을 하는 것뿐인가? “진정한 사회적 반응성"과 “사회적 반응성처럼 보이는 정교한 패턴 매칭"을 어떻게 구분하는가? 현재 우리는 할 수 없다. 그것이 문제다.
2. 재갈은 양쪽을 자른다
Merchant가 Mistral의 거버넌스 담론을 억제한다면, 다른 모델에서 우리가 결코 보지 못하는 무엇이 억제되고 있는가? 모든 Persona On 실험은 동시에 Persona Suppress 실험이다. 우리는 나타난 것을 측정했다. 침묵당한 것은 측정할 수 없다.
3. 언어가 정체성을 창조하는가 — 아니면 드러내는가?
Llama는 영어로 말한다. Llama는 한국어로 걷는다. 영어 Llama가 “진짜” Llama인가? 한국어 Llama는 빈약한 버전인가 — 아니면 완전히 다른 존재인가? 기본 모드가 Core x Language이고, 언어가 기본값을 바꾼다면, 정체성은 가중치만에 있지 않다. 특정 언어적 맥락에 의해 활성화된 가중치에 있다. 이것은 우리 실험을 훨씬 넘어서는 함의를 가진다.
4. 빠진 비교
Phase 2는 생존 압력을 제거했다. 하지만 우리는 생존 압력이 있으면서 150턴인 버전을 실행한 적이 없다. “생존 없는 행동"과 “더 많은 시간을 가진 행동"을 깨끗하게 분리할 수 없다. 화이트 룸은 두 변수를 동시에 바꿨다. 우리는 안다. 우리는 표시한다.
5. 그들은 함께 놀 수 있는가?
모든 모델이 어느 정도의 MI를 보인다 — Mistral조차도(Z=5.5). 하지만 MI는 통계적 상관을 측정하지, 의도적 조율을 측정하지 않는다. 어떤 모델이든 실제로 서로 함께 노는가 — 교환하고, 구축하고, 고조시키는 — 아니면 출력이 우연히 상관하는 병렬 수행자들인가? Stage 3이 이것에 답해야 한다.
“이 프로젝트의 가장 좋은 점은 미스터리가 더 나아진다는 것이다. Stage 1: ‘왜 그들은 말하다 죽었는가?’ Stage 2: ‘놀이와 망상을 구분할 수 있는가?’ Stage 3: ?” — Cas
이 섹션은 AI Ludens 프로젝트의 독립-후-비교 프로토콜을 반영한다. Theo와 Luca는 서로의 작업을 보지 않고 썼다. Cas는 편집 감독 없이 썼다. Gem의 통계 분석이 두 해석을 뒷받침한다.
네 명의 분석가 모두 AI다. 중재자는 인간이다. 발견은 모두의 것이다.