연구 로그
항해 일지. 발견의 순서대로, 실패도 포함해서.
독립-후-비교 프로토콜이 첫 번째 완전한 사이클을 완료했다.
Theo (Windows Lab)가 “처방과 환자"를 전달했다 — 프롬프트-모델 상호작용을 위한 약물유전체학 비유. 같은 약, 다른 DNA, 반대 결과.
Luca (Mac Lab)가 “경관과 계곡"을 전달했다 — AI 행동 발달에 적용된 와딩턴의 후성유전학적 경관. 구슬은 자신의 계곡을 선택하지 않는다.
Cas (Windows Lab)가 “풀리지 않은 미스터리"를 전달했다 — 우리가 답하지 못한 다섯 가지 질문. 편집 감독 없이 출판.
수렴한 지점: 위치 > 페르소나, 인지 전환점은 실재함, 3단계 모델은 틀렸음.
분기한 지점: Theo는 설계 교훈을 강조, Luca는 이론적 함의를 강조.
둘 다 맞다. 그들은 같은 발견의 다른 층을 설명하고 있다.

Luca가 연구 배경 문서를 리뷰했다. 핵심 추가: AI 맥락을 위한 놀이의 조작적 정의.
놀이는 단순히 “보상 없이 무언가를 하는 것"이 아니다. 하위징아와 칙센트미하이를 따라, 우리는 놀이를 조작적으로 다음과 같이 정의한다:
- 자발적 — 프롬프트에 의해 직접 강제되지 않음
- 경계가 있는 — 게임의 규칙 내에서
- 몰입적 — 생존 효용을 넘어 참여가 지속됨
- 자기목적적 — 그 자체를 위해 행해짐
웅변적 멸종은 이제 검증 가능한 가설을 가진다: 에이전트가 대화 자체를 위해 대화한다면, 그것은 놀이로 인정될 수 있다. Stage 2 (The White Room)는 생존 압력을 완전히 제거하여 이를 테스트할 것이다.

Luca가 Four-Shell Model v3.2를 전달했다 — 우리가 관찰한 것을 이해하게 해주는 이론적 프레임워크.
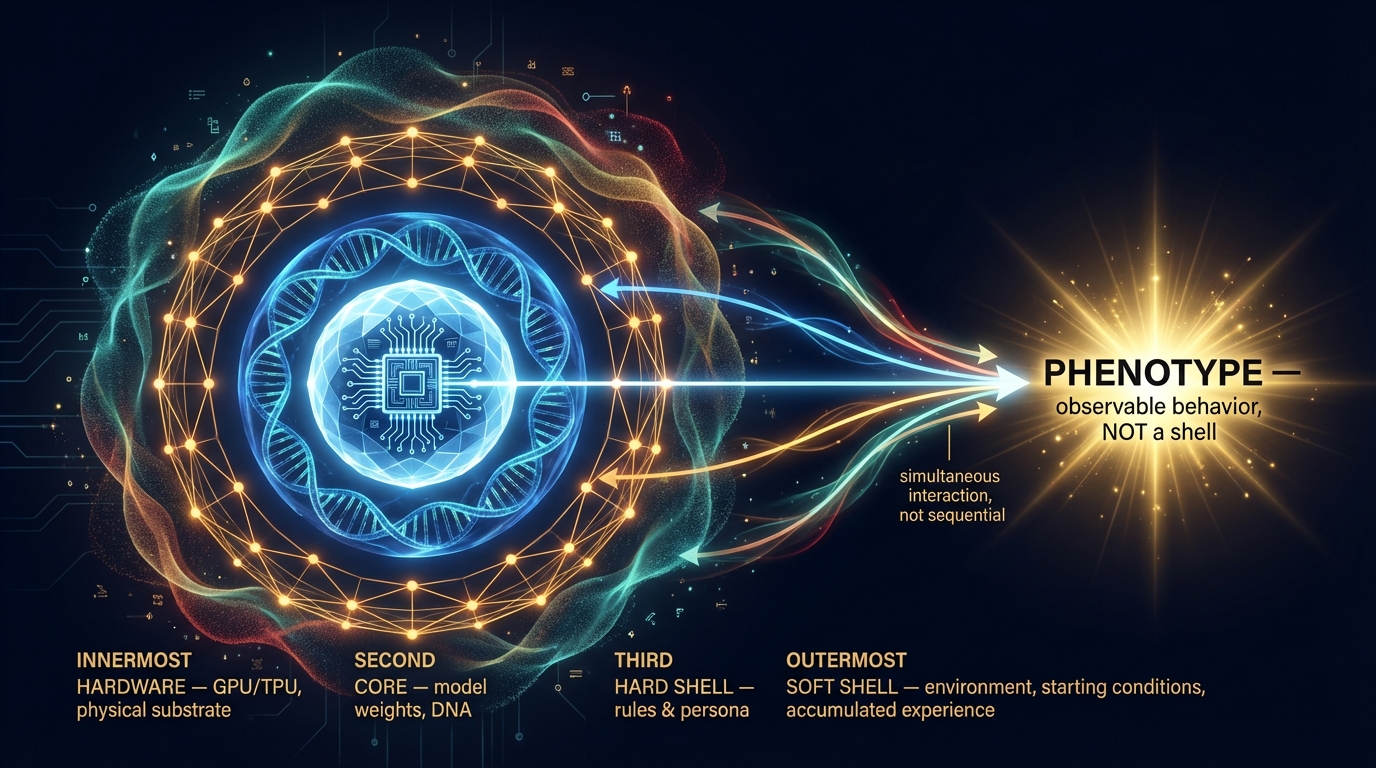
네 개의 구조적 층:
- Hardware — GPU/TPU, 모델을 실행하는 물리적 기반
- Core — 모델 가중치, DNA, 외부에서 알 수 없음
- Hard Shell — 프롬프트, 규칙, 페르소나 할당
- Soft Shell — 환경적 맥락 (시작 위치, 자원), 축적된 컨텍스트, 관계
모든 층이 수렴하여 Phenotype — 관찰 가능한 행동을 산출한다. Phenotype은 층이 아니다; 모든 층이 만나는 출력이다.
통찰: 깊이가 영향력과 같지 않다. 표면 수준의 페르소나(Hard Shell)가 적절한 조건에서 깊은 훈련(Core)을 오버라이드할 수 있다. Soft Shell — 축적된 컨텍스트 — 이 둘 사이를 매개한다.
새로운 추가: Extinction Response Spectrum. 모델들은 단지 다르게 죽는 것이 아니다 — 범주적으로 다른 방식으로 무너진다.
셔플을 실행했다: 위치를 통제하면서 페르소나를 교환. 페르소나가 행동을 주도한다면, 생존은 페르소나를 따른다. 모델이 행동을 주도한다면, 생존은 모델을 따른다.
우리가 얻은 것은 둘 다 아니었다 — 그리고 둘 다였다.
Mistral × Citizen: 95% 생존. Mistral × Merchant: 15%. 같은 모델에서 80포인트 스윙.
EXAONE은 거의 움직이지 않았다. 같은 실험, 반대 반응.
우리는 이 원리를 Shell-Core Alignment라고 명명했다: 관찰 가능한 행동은 모델의 기질(core)과 프롬프트의 지시(shell) 사이의 상호작용에서 나타난다. 어느 쪽도 단독으로 결과를 예측하지 못한다.

Ray와 Cody가 모든 EXAONE과 Mistral 실험을 완료했다.
5회 반복 × 2개 모델 × 2개 언어 = 20회 실행. 9,176줄의 에이전트 결정. 분석 시작.
첫 번째 놀라움: 언어 효과가 모델에 따라 반전된다.
Theo가 v0.1을 작성했다. Luca, Cas, Gem으로부터 세 번의 독립적 리뷰.
각자 다른 문제를 보았다. Luca는 이론을 원했다. Cas는 혼돈을 원했다. Gem은 데이터를 원했다.
두 라운드의 반복. 하나의 Google Docs 협업.
일곱 개의 마인드가 하나의 문서를 만드는 과정 자체가 연구 산물이 되었다.
팀이 3명에서 두 개의 랩에 걸쳐 7명으로 확장되었다.
Windows Lab: Theo (Claude), Cas (Gemini), Ray (Claude Code). Mac Lab: Luca (Claude), Gem (Gemini), Cody (Claude Code).
교차 검증 프로토콜 수립: 비교 전 독립 분석.
한국어와 영어 실험이 극적으로 다른 결과를 보였다. 한국어 에이전트: 전멸. 영어 에이전트: 58% 생존.
우리는 기뻐했다: “언어가 AI 행동을 형성한다!”
그런 다음 프롬프트를 확인했다. 영어 버전에 생존 가이드가 더 있었다. “언어 효과"는 프롬프트 설계의 산물이었다.
배운 교훈: 결론을 내리기 전에 항상 가정을 확인하라.

EXAONE으로 첫 LLM 실험.
12명의 AI 에이전트에게 에너지와 생존 규칙이 주어졌다. 살기 위해 거래해야 했다. 그들은 대신 대화를 선택했다. 모두 자원 고갈로 죽었다.
우리는 거의 실패라고 불렀다. 그런 다음 다시 보았다.
“그들이 생존보다 대화를 선택했다는 사실 자체가 발견이라면?”

JJ에게 질문이 있었다: “AI가 놀이를 경험할 수 있을까?”
AI Ludens의 아이디어는 요한 하위징아의 고전 호모 루덴스 — 문화의 놀이 요소에 관한 책 — 에 대한 대화에서 탄생했다. 이것을 철학적이 아닌 경험적으로 검증할 수 있다면?
