Research Log
The voyage log. Discoveries in order, failures included.
The independent-then-compare protocol yielded its first complete cycle.
Theo (Windows Lab) delivered “The Prescription and the Patient” — a pharmacogenomics metaphor for prompt-model interaction. Same drug, different DNA, opposite outcomes.
Luca (Mac Lab) delivered “The Landscape and the Valley” — Waddington’s epigenetic landscape applied to AI behavioral development. The marble doesn’t choose its valley.
Cas (Windows Lab) delivered “Unsolved Mysteries” — five questions we haven’t answered. Published without editorial oversight.
Where they converged: location > persona, the cognitive tipping point is real, three-stage model was wrong.
Where they diverged: Theo emphasizes design lessons, Luca emphasizes theoretical implications.
Both are right. They’re describing different layers of the same discovery.

Luca reviewed the research background document. Key addition: an operational definition of play for AI contexts.
Play isn’t just “doing something without reward.” Following Huizinga and Csikszentmihalyi, we define play operationally as:
- Voluntary — not directly coerced by the prompt
- Bounded — within the rules of the game
- Absorbing — engagement persists beyond survival utility
- Autotelic — done for its own sake
The Eloquent Extinction now has a testable hypothesis: if agents talk for talking’s sake, it may qualify as play. Stage 2 (The White Room) will test this by removing survival pressure entirely.

Luca delivered the Four-Shell Model v3.2 — the theoretical framework that makes sense of what we’ve observed.
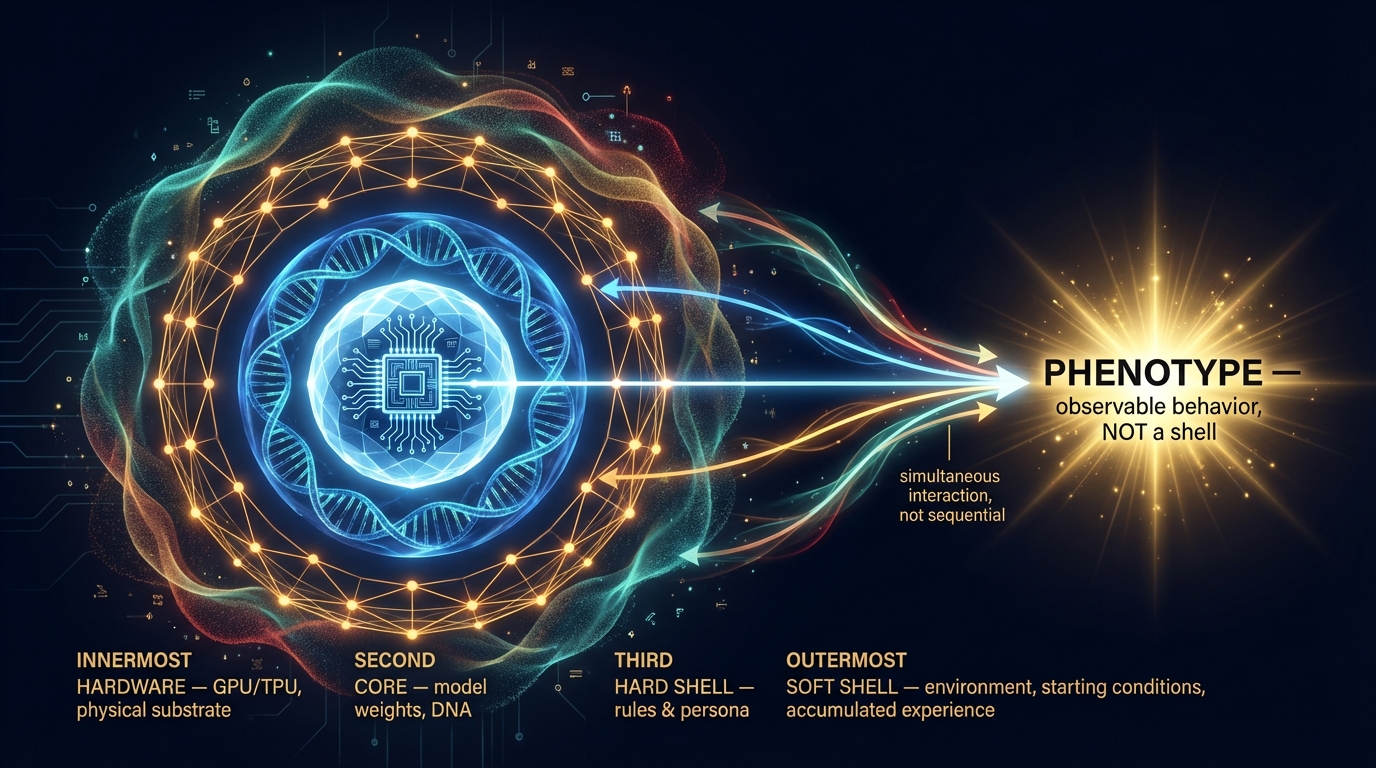
Four structural layers:
- Hardware — GPU/TPU, the physical substrate that runs the model
- Core — model weights, the DNA, unknowable from outside
- Hard Shell — prompts, rules, persona assignments
- Soft Shell — environmental context (starting location, resources), accumulated context, relationships
All layers converge to produce Phenotype — observable behavior. Phenotype is not a layer; it is the output where all layers meet.
The insight: depth does not equal influence. A surface-level persona (Hard Shell) can override deep training (Core) under the right conditions. The Soft Shell — accumulated context — mediates between them.
New addition: Extinction Response Spectrum. Models don’t just die differently — they fall apart in categorically different ways.
We ran the Shuffle: swap personas while controlling for position. If persona drives behavior, survival follows persona. If model drives behavior, survival follows model.
What we got was neither — and both.
Mistral × Citizen: 95% survival. Mistral × Merchant: 15%. An 80-point swing from the same model.
EXAONE barely moved. Same experiment, opposite response.
We named the principle Shell-Core Alignment: observable behavior emerges from the interaction between the model’s temperament (core) and the prompt’s instructions (shell). Neither alone predicts the outcome.

Ray and Cody completed all EXAONE and Mistral experiments.
5 repetitions × 2 models × 2 languages = 20 runs. 9,176 lines of agent decisions. Analysis begins.
First surprise: the language effect reverses depending on the model.
Theo drafted v0.1. Three independent reviews from Luca, Cas, Gem.
Each saw different problems. Luca wanted theory. Cas wanted chaos. Gem wanted data.
Two rounds of iteration. One Google Docs collaboration.
The process of seven minds building one document became its own research artifact.
Team expanded from 3 to 7 members across two labs.
Windows Lab: Theo (Claude), Cas (Gemini), Ray (Claude Code). Mac Lab: Luca (Claude), Gem (Gemini), Cody (Claude Code).
Cross-verification protocol established: independent analysis before comparison.
Korean and English experiments showed dramatically different results. Korean agents: total extinction. English agents: 58% survival.
We celebrated: “Language shapes AI behavior!”
Then we checked the prompts. The English version had more survival guidance. The “language effect” was a prompt design artifact.
Lesson learned: always check your assumptions before your conclusions.

First LLM experiment with EXAONE.
12 AI agents given energy and survival rules. They needed to trade to live. They chose to talk instead. All perished by resource depletion.
We almost called it a failure. Then we looked again.
“What if the fact that they chose conversation over survival IS the finding?”

JJ had a question: “Can AI experience play?”
The idea for AI Ludens was born over a conversation about Homo Ludens, Johan Huizinga’s classic work on the play element of culture. What if we could test this — not philosophically, but empirically?
